
数据清洗,是进行数据分析和使用数据训练模型的必经之路,数据分析师经常需要花费大量的时间来清洗数据或者转换格式,这个工作甚至会占整个数据分析流程的80%左右的时间。
数据清洗的目的有两个,第一是通过清洗让数据可用;第二是让数据变的更适合进行后续的分析工作。通常来说,你所获取到的原始数据不能直接用来分析,因为它们会有各种各样的问题,如包含无效信息,列名不规范、格式不一致,存在重复值,缺失值,异常值等…
以下是我们这期要进行处理医学相关的数据,包含了一些化学含量数据,例如酒精、苹果酸、镁、黄铜、花青素等,本篇就这份数据顺便分享一些比较便捷实用的数据清洗技巧。
1、导入分析包
数据清洗主要用到的就是numpy以及pandas库,在处理前确保安装好该库。

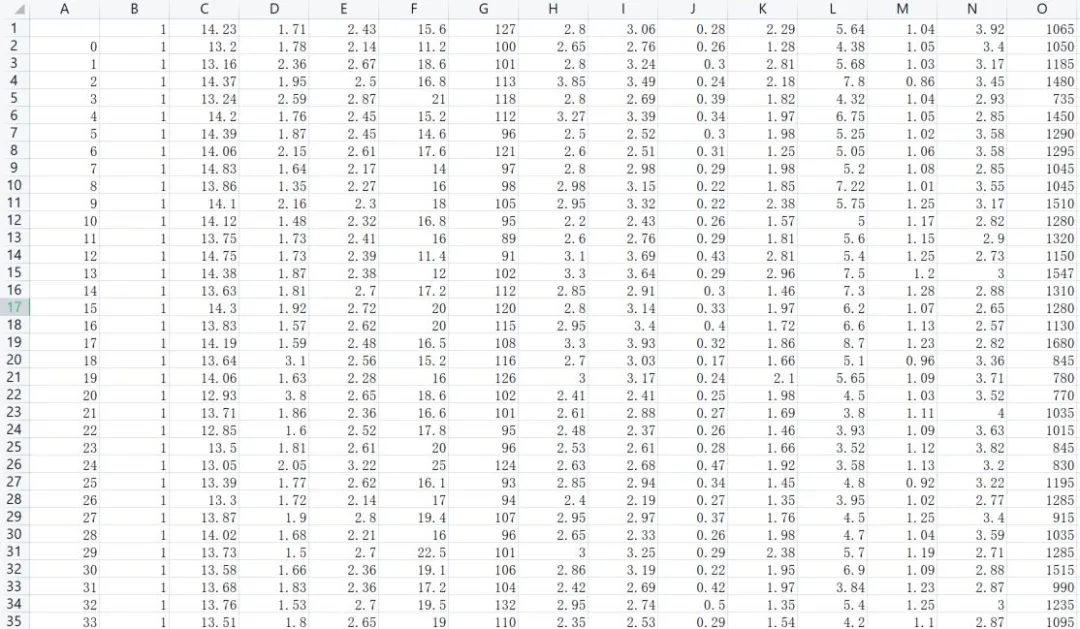
2、加载数据集
这里对数据进行了预览,确保数据无误。
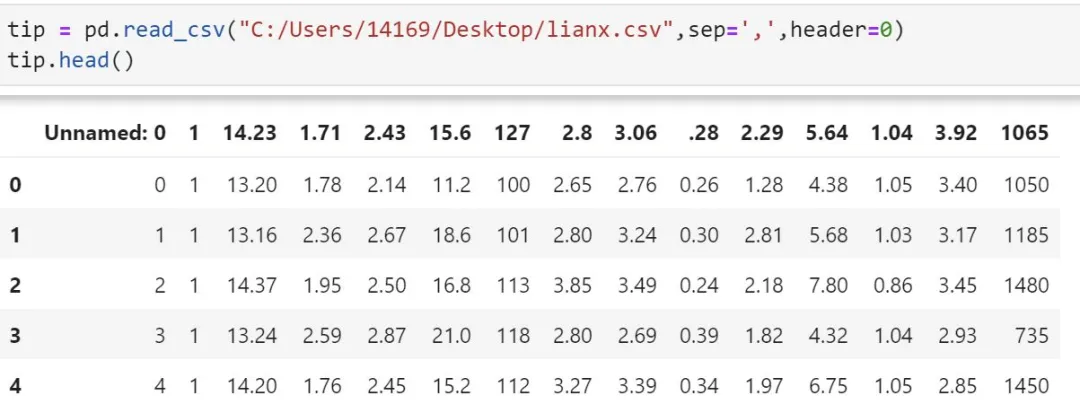
3、对某一字段进行清洗
例如这里我想删除第 1,4,7,9,11,13,14列,并保存修改,操作如下:

4、添加列索引
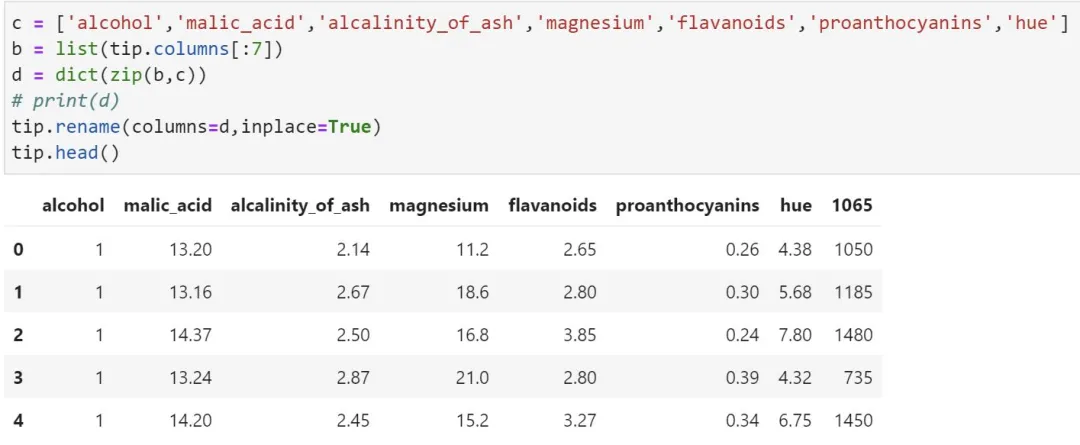
5、数据替换
5.1 将alcohol 这一列的前三行改为NaN
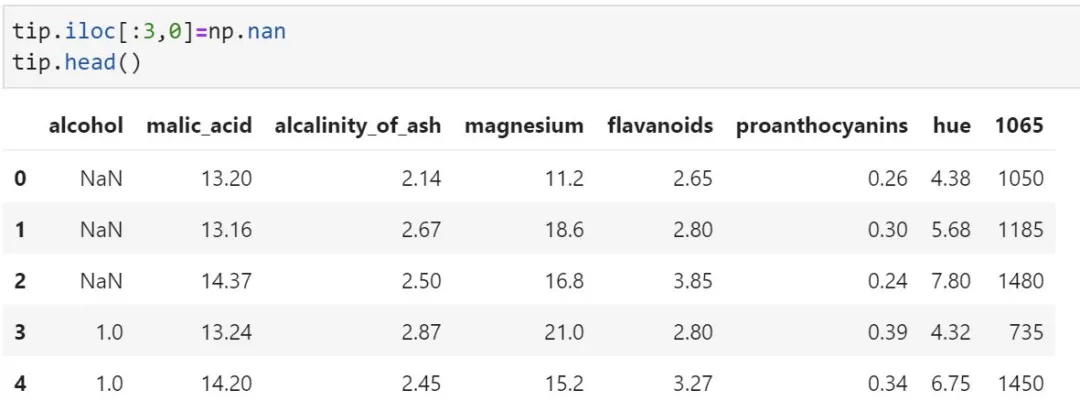
5.2 设置magnesium的第3到4行为NaN
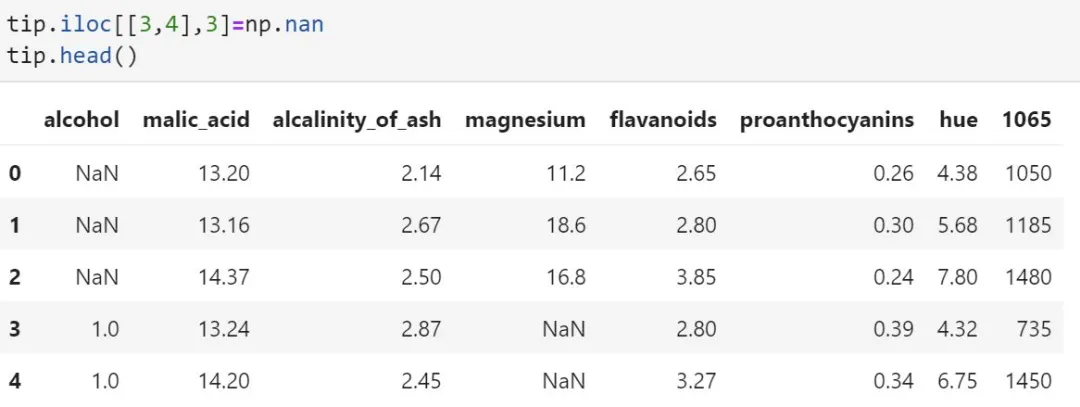
6、缺失值处理
对于缺失值有两种处理的方法
第一种是使用fillna函数对空值进行填充,可以选择填充0值或者其他任意值
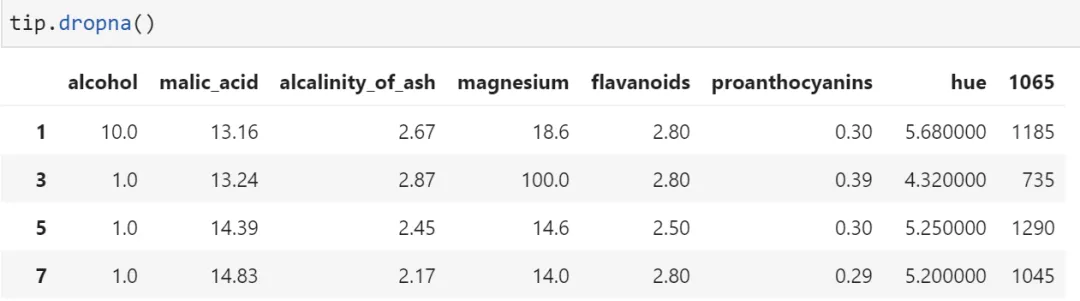
第二种方法是使用dropna函数直接将包含空值的数据删除
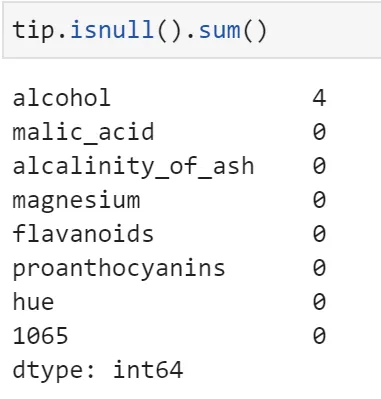
6.1 将 alcohol 和 magnesium列的缺失值分别用10和100进行填充

6.2 统计缺失值个数
6.3 删除包含缺失值的行
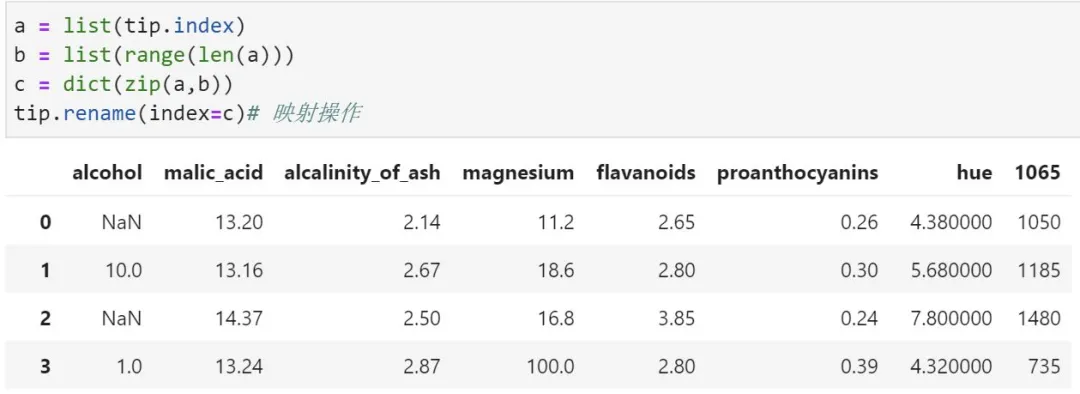
7、数据整合
让索引重新从0开始
受教了,作为一个刚接触数据清洗的小白长见识了,感谢博主!
This is a great article that has taught me a lot. By the way, your website is very beautiful. Can you write a tutorial on building it?
刚转行到数据分析行业,以前搞java的,接到任务一脸懵逼,不过照着你的教程敲了个demo之后基本上算是入门了,感谢博主!
666666666666666
写的很清晰,谢谢!
Some really prize content on this site, saved to fav. Maximo Griffie
I love looking through a post that will make people think. Also, many thanks for permitting me to comment. Josiah Damiani
Awesome post. Really looking forward to read more. Want more. Jean Olwin
I was examining some of your articles on this website and I think this site is rattling informative ! Keep on putting up. Jackie Skokowski